Attention is All They Need
If you’ve spent any time reading computer vision papers over the past few years, you’ve probably noticed a big change in the way papers look, driven by the deep learning revolution and following boom in computer vision. We (me, Gabe Appleby, David Crandall and Norman Su) wrote a paper about these changes, and how they both reflect and shape computer vision. If that sounds interesting, read our paper!

Some of the teaser images from recent CVPR papers.
We became interested in this topic because of David and Norman’s prior work on the “Affective State” of computer vision. They asked computer vision researchers to submit anonymous short stories, analyzed their text for emotion terms and found “a general mood of malaise” in the field. We wanted to figure out why, and realized that there might be clues in papers themselves. To study these papers, we combined three approaches: looking at historical papers from digital repositories, interviewing veteran researchers and writing code to analyze the text of open access papers. We ended up focusing on three aspects which have changed over time:
-
Advertising the contribution: elements of the research paper which serve to attract the attention of possible readers. These are things like the “teaser image” and particular title constructions. We noticed that many of these teaser images, like the two pictured above, look surprisingly like advertisements for the paper’s contribution. This isn’t a bad thing — as our research participants explained it helps make the papers easier to read and “just makes them look good.” These trends interact with the increased role of the preprint server arXiv and social media for academic research. They also showcase how the benefits of research, like jobs, promotions and good employees rely on competing in an attention economy for other researchers’ time.

Notice how the teaser images show the same sort of side-by-side comparisons as the paper towel advertisement.
-
Measuring the contribution: results tables which demonstrate improvement over prior work. These tables have started to show up in almost every paper, and as authors are expected to provide more baseline comparisons, they get bigger too. The development of these tables shows computer vision’s shift from a mathematical discipline based on geometric proofs towards an empirical discipline based on quantitative metrics, and have changed the way papers relate to one another: the researchers we interviewed now see their work as inherently competitive, and use lots of market-based language when talking about conference publishing.
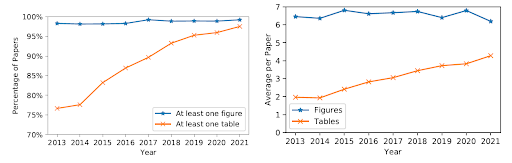
Today, almost every CVPR paper has a table, and the number of tables per paper doubled in ten years.
-
Disseminating the contribution: elements of papers which rely on digital PDFs and arXiv instead of paper conference proceedings for publishing. These are things like high resolution figures, like the two pictured above, which have tiny text which isn’t visible on a printed page, and accessibility features which can’t exist on paper. These features point to the changing role of conferences. In the past, conferences became popular in computer vision because they were much faster than journals, and the limiting factor on publication was the conference’s printing budget, and conferences would print as many technically correct submissions as they could fit. But now, arXiv is filling that role, and the limiting factor on conference publishing is the attention of other researchers. That means peer reviewers have to do a much bigger job! Instead of filtering submissions to fit the budget, reviewers now serve to measure the value of research work. In the words of a participant they are “the biggest benchmark by which you are evaluated” as a researcher.
We found several papers which combined several data visualizations into a tiny fraction of the page, with text too small to reproduce using a standard office printer.
All of these trends point towards the increased commodification of computer vision research. By commodification, we mean a process by which research work is treated as interchangeable, given some measure of its value. That can be like a benchmark, where a contribution over existing methods might be literally depicted as a bolded green number with an up arrow next to it, or a more conceptual evaluation like conference review scores or citation counts which represents the attention of other researchers. Based on Marxist theories of alienation, we believe that these trends are contributing to a “mood of malaise” observed in computer vision, which also impacts the larger-scale commodification of crowd worker intelligence. These workers label data, often valued at a few cents per task, in order to create the measurably larger datasets and measurably better models so researchers can compete for the attention of their discipline.
We worry that these trends in paper-writing may be constraining the work done in computer vision. These trends foster a mindset of technological determinism, where researchers believe that all possible visual perception tasks have optimal computational solutions, and research is only a matter of finding them first, rather than thinking more critically about whether visual perception is the right approach. We also worry that these trends may be contributing to bias and injustice issues in machine learning, since researchers are incentivized to write like advertisers and turn a blind eye to the limitations of their work. There is a risk that engineers or researchers who are unfamiliar with this system might take the claims in research papers at face value, and put minimally-explored methods into production.
In any case, we recommend that the computer vision conferences consider a substantial redesign of their submission, review and publishing practices. The current accelerating pace of publication is clearly unsustainable and harmful to students, and there’s got to be a different design which adjusts the limiting factors to avoid placing so much pressure on reviewer attention. While we’re not quite sure what that alternative is yet, we think approaching it from a design perspective will be helpful.