Survey Results and Answers
4/15/17
Well, it’s been a month, and I finally have a free day to write up the answers to the survey! People had been asking whether they got the right answers, and since my results were anonymous, I couldn’t just look it up. That said, I figured it would be fun to make a post with some graphs.
The Questions
First, here is the text of my survey.
Thank you for agreeing to help me complete my Honors project! First, please answer some demographic questions, then answer a few questions related to music samples, which will be in the form of links to Soundcloud pages. Make sure you either have headphones or are in a space where you can listen to music before beginning! If you have any questions or issues, feel free to contact me at sgoree @ oberlin.edu!
What is your age?
-
Under 18 years old
-
18-24 years old
-
25-39 years old
-
40-54 years old
-
55-69 years old
-
70 years old or older
Which of the following best identifies you?
- “I am a musician or music enthusiast who has studied the music of J. S. Bach”
- “I am a musician or music enthusiast, though I have not studied the music of J. S. Bach”
- “I am not a musician or music enthusiast”
Please identify your race/ethnicity:
- White
- Hispanic or Latino
- Black or African American
- Native American or Alaska Native
- Asian, Native Hawaiian or Pacific Islander
- Other
Please identify your gender:
- Male
- Female
- Non-binary
- Other
* Participants are asked the following questions four times *
For the next three questions, please base your answers on this sound sample:
* Below is an embedded SoundCloud player for one of 24 possible sound samples, three from each of the eight categories discussed in the results section *
Do you think this music was composed by J. S. Bach or a computer?
The “Correct” Answers
There were 24 sound samples:
(If the embedding isn’t working, you can also access them here)
The human/computer breakdown is as follows:
- Samples 1-3 are the simple model generating a melody
- Samples 4-6 are the product model generating a melody
- Samples 7-9 are melodies from Bach chorales
- Samples 10-12 are simple model harmonizations of a Bach melody
- Samples 13-15 are product model harmonizations of a Bach melody
- Samples 16-18 are full Bach chorales
- Samples 19-21 are simple model fully generated chorales
- Samples 21-24 are product model fully generated chorales
What does that mean? For the details on the models themselves, see a previous post. For the different generation schemes (melody-only vs. harmonization vs. fully generated), since I never wrote that post, melody only means running one model to generate a replacement voice for an existing chorale, then taking that new voice out of context. Harmonization is taking the melody from a Bach chorale (which usually is an older lutheran hymn) and using three models, one trained on each other voice, to generate the other three voices, and full generation is four models, trained on each voice, generating an entire chorale with none of Bach’s writing.
Your Answers
I got 244 responses, about 180 were complete. The demographic breakdowns speaks more to the departments that I sent the survey to at Oberlin and the set of people who are less than two degrees of separation from me on Facebook.
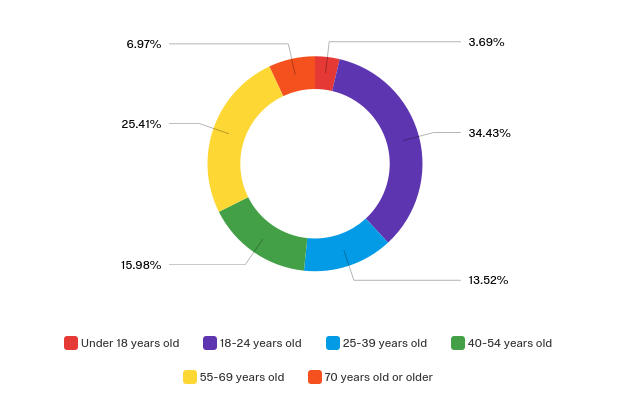
Age Demographics:
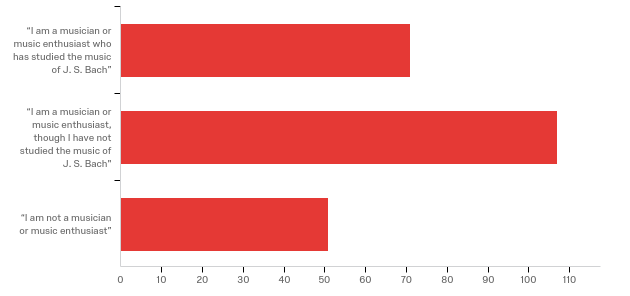
Music Experience Demographics:
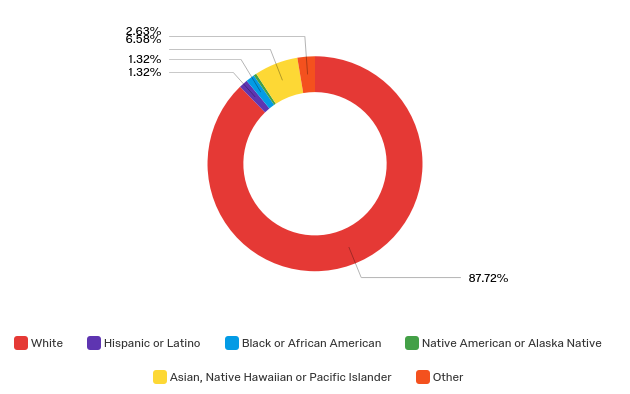
Race Demographics:
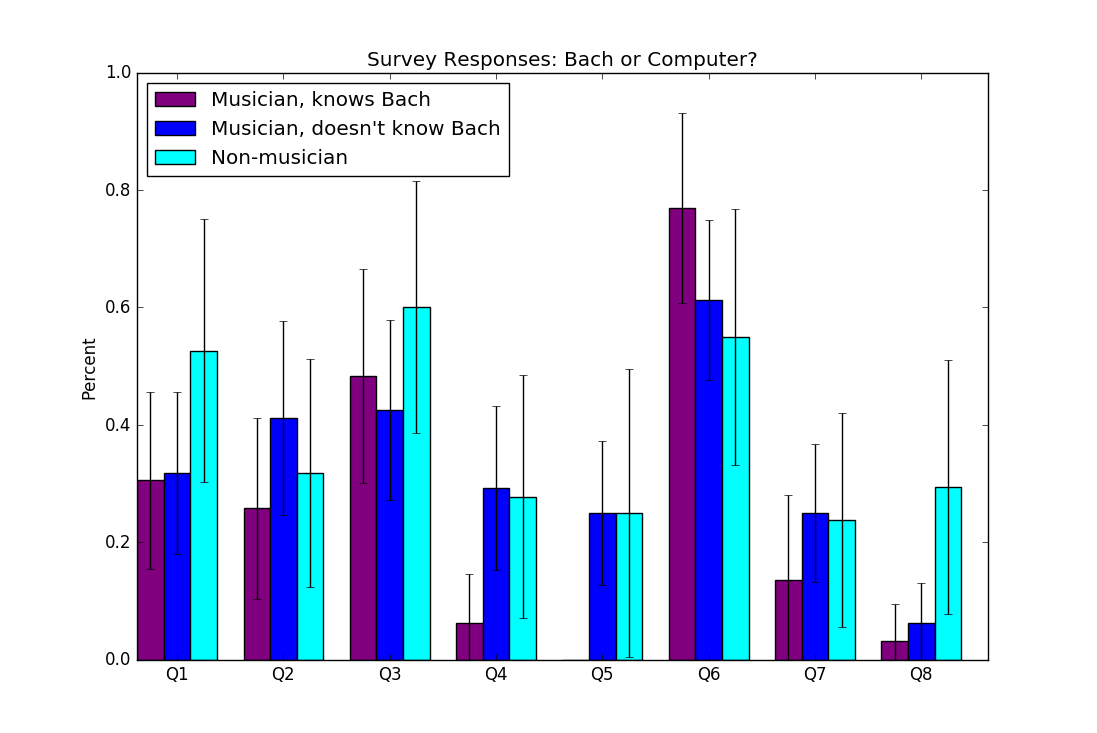
These are the answers to the music questions. Here, Q1 through Q8 are the eight different categories of samples discussed above.
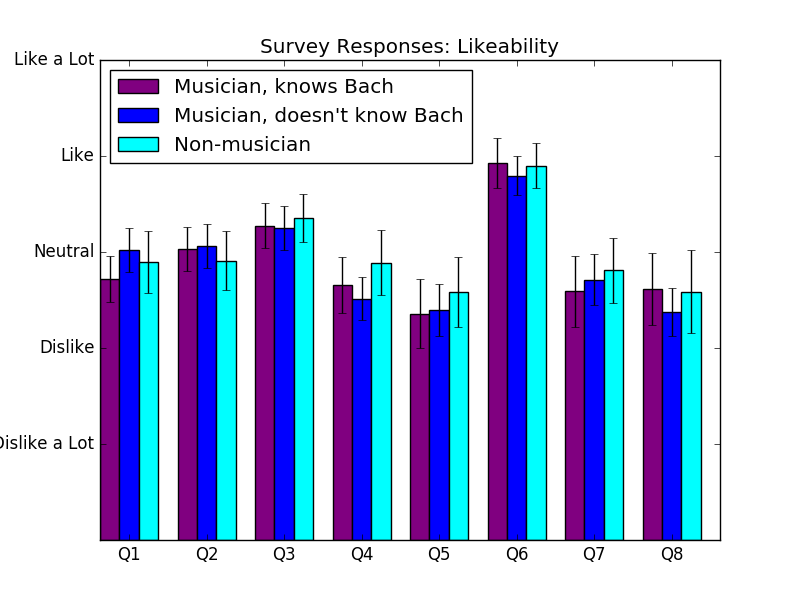
I also asked people for their comments on various samples.
-
simple melody
- Sounded like something a child would create on the piano. Kind of boring and repetitious notes.
- I voted Bach simply because the simplicity makes it seem like I’m “supposed” to guess computer.
-
product melody
- felt more human but lacked natural dynamics based on humans hitting the keys with different forces
- The melody made it difficult to find the tonality. I couldn’t get a sense of what the root was.
-
Bach melody
- Because it feels relatively repetitive, I suspect that it was composed by a computer, but I felt it had more human feeling to it than the previous sample.
- Coherent phrases!! Much better. This music not only sounds better, but it makes a lot more sense than any of the others so far.
-
simple harmonization
- Is this being played on a computer as opposed to on a piano or electronic keyboard and then recorded? It has an industrial sound that made it hard to figure out. Could be Bach. Not sure. Thought I heard a familiar tune there.
- Very Charles Ives.
- Aesthetically, I enjoyed it because of how it flirted between dissonance and familiar consonance, but it was nowhere close to following the “traditional” harmonic conventions of Bach so as far as pure believability goes, it didn’t sell me.
-
product harmonization
- I don’t have a solid reason for voting Bach, but it was perhaps the most realistic-sounding piece yet. Even though there were still some clashing notes, they still have an underlying harmonious balance and do eventually resolve.
- Ugh sounded like someone was just pounding randomly on the piano…very uneven and unpleasant
- there was little to no overarching structure, the rhythm was disjointed and unresolved dissonance prevailed
-
Bach chorale
- The performance (which I suspect may be computer-generated rather than played) is so unyielding rhythmically (i.e. devoid of accent) that it was annoying to listen to. (I wrote that I enjoyed it, which I did, but through a kind of filter of annoyance. I couldn’t have taken much more of it.) I base my ``computer’’ answer partly on not recognizing it, and partly on a kind of hyper-regularity to the composition that doesn’t remind me of JSB at all.
- The structure was strong in this one, and what I know to expect from Bach.
-
Simple generation
- The having multiple chords made me think it was Bach at first, but now I think it’s too jumbled and discordioate.
- Like the previous two, nothing Bach-like about the harmonic or rhythmic idiom. It has a kind of fluidity that I liked better than the previous two.
- You could tell the composition was Bach but some notes fell into each other \& some were jarring.
-
Product generation
- Very atonal, tho some of the rhythmic aspects were similar to a Baroque style
- This one has a lot of notes that sound discordant to me, which makes me think it should be human because a computer should know which notes not to put together, full stop, and shouldn’t be able to break the rules? But at the same time, it sounds so bad I have difficulty believing a human made it.
And some of my favories:
- Bach or computer, this miserable fragment has been punished more than sufficiently by an unbelievably crude machine performance.
- Holy Midi, batman! Not necessarily a bad melody, but that gets lost in the tiny mide
- What the fuck was going on in the beginning. Who decided these chords were a good idea. What kind of train wreck happened there at 0:25. What. If I knew this was the baseline for how the computer does, I would have changed my previous answers So Much. SO much, Sam. So much discord going on. Eugh. No.
- It’s lit fam
So what does it mean?
Some observations about this data copied from my paper follow.
First, There was no significant difference between the two models for melody generation or harmonization, but there was for full chorale generation: the simple model outperformed the product model. This may have been because the product model became too reliant on the spacing with another voice. In Bach’s music, all of the voices imply each other to some extent, and assuming that one voice perfectly implies another is dangerous when dealing with generated voices.
That said, we cannot conclude with any certainty that the product model is a flawed approach. Since it is a larger neural network with more parameters, it is more likely to train into a local minimum and may perform substantially better with more training data. Additional training with a larger chorale dataset may result in higher quality musical output.
Second, generated melody samples were much more difficult for participants to differentiate from real Bach than four part harmony samples.
Third, the nature of the training data inadvertently allowed the simple model to pick up aspects of tonality, since most of the pieces were in keys that had several notes in common, that the model learned to prioritize. Importantly, though, this did not restrict the model to a specific set of pitches or impose unwanted assumptions, but it did reduce the amount of dissonance in the music it composed, especially when generating from scratch.
Fourth, synthesis, or the process of creating sound electronically from scratch, played a greater role in both participants’ and our expert’s evaluation of samples than expected or intended. People had a tendency, as displayed by the comments on samples, to evaluate based on timbre (instrument sound qualities) and expressiveness rather than pitches and rhythms, and were convinced that even the Bach samples were computer-composed just because they were computer-synthesized. It is possible that many participants may have rated all of the samples higher if they had been performed by humans or more sophisticated synthesizer systems rather than just MIDI.
Finally, musical form and structure, even in a piece as short as a chorale, remains an unsolved problem. The lack of correct melodic syntax, which for a chorale means having a coherent beginning, middle and end to each phrase, was a sticking point both with survey participants and our expert for many samples, and is clearly not something LSTM networks can learn without external guidance. Future researchers may want to look into quantitative measures of consonance and dissonance and potentially train a consonance expert which is only trained on intervals’ consonance values. Since dissonance is a subjective and often culture-specific phenomenon, though, more research is necessary before a model like this could be proposed.
To all who participated, thank you very much for helping with my research! I hope you found this discussion satisfying!